Choosing the Right Implementation Between ArrayList and LinkedList
Introduction
The Collection Frameworks give you two implementations of the List interface: ArrayList and LinkedList. Is there one that is better than this other? Which one should you choose in your application? This section goes through the difference of both implementations, examine the performance of the operations they offer, and measures the memory footprint, so that you can make the right choice for your use case.
Algorithm Complexity
Algorithm Complexity for Some Common List Operations
The starting point of all the discussions you can find here and there about the differences between array-based lists and linked lists is about algorithm complexity, measure with this notation O(n). The complexity of the different operations offered by the List interface is usually described as being O(1), O(n) or even O(ln(n)).
Let us compare this complexity for three basic operations.
- Getting an element from the list. And because there is a difference, let us compare the getting of an element from the beginning of the list, the end of the list, and the middle of the list.
- Iterating over the elements of the list. Once again, you have (at least) two patterns to do that: iterating with an index, or with an
Iterator. - Inserting an element. And again, because there is a difference, let us compare the insertion of an element at the beginning of the list, the middle of the list, and the end of the list. Even if this last one is not really an insertion.
We will not compare the replacement of an element by another, because it is actually the same as reading the element you want to replace.
Here are the complexity of all these operations, as you can find them in any good book on data structures.
| Operation | ArrayList | LinkedList |
|---|---|---|
| Reading first | O(1) | O(1) |
| Reading last | O(1) | O(1) |
| Reading middle | O(1) | O(n) |
| Adding last | O(1) | O(1) |
| Inserting first | O(n) | O(1) |
| Inserting middle | O(n) | O(n) |
This is all good, and there is not many differences between both: LinkedList is O(n) for two operations: reading middle and inserting middle.
Two points are worth noting on these operations.
First: reading last is O(1) on LinkedList because this implementation carries a direct reference to the last element of the list.
Second: the operations on ArrayList are not the same as the operations on LinkedList. For ArrayList the operation consists in moving an array of size n from one place to another, where for LinkedList the operation consists in following n references to find the element you need to work on. We need to precisely measure the cost of these two operations.
What Does Algorithm Complexity Mean?
This O(n) notation mean that, past a certain threshold, the time it takes for the algorithm you are working on to process your data is proportional to the amount of data (n). Simply said, if the amount of data you process is above this threshold, doubling this amount also doubles your processing time. For a O(1) complexity your algorithm does not depend on the amount of data you are processing. This is only logical: reading the first element of a list does not depend on the size of your list.
So this O(n) notation actually gives you the asymptotic behavior of your algorithm. The important point of the previous definition is past a certain threshold. What is the value of this threshold, and how does it compare to the amount of data you are processing in your application?
Suppose that you are executing an algorithm on some data. And you know that the amount of operations this algorithm executes is exactly a*n + b. Suppose now that a = 10 and b = 1. Then if you are processing 10 or more elements, making the assumption that your algorithm executes in n gives you an error of less than 1%. But if a = 1 and b = 10, then saying that your algorithm executes in n is only valid for the processing of 1_000 or more elements. Your threshold was 10 in the first example, and 1_000 in the second one.
The point is: knowing that your complexity is O(n) is interesting, but you need to know more. How does it apply to your use case? What is the value of the threshold for your application? Obviously, if the threshold is 1_000, and you are processing 100 elements at a time, then this formula doesn't apply to your use case.
LinkedList interface and ArrayList are not working in the same way, at all. There are hidden mechanisms internally that have an impact on performance, that goes way beyond the simple algorithm complexity. The rest of this section goes through all of them, to help you make an informed decision.
Reading Elements From a List
Let us create a first benchmark, that consists in reading elements from a list:
- The first element,
- then the last element,
- then the element in the middle.
Because we expect to have different results when the size of the list varies, we are going to run the benchmark for different sizes.
Note that all the benchmarks you can see on this page have been made with JMH, the only tool you should be using to measure performance in a reliable way.
Reading the First and the Last Element of a List
The code we are running this benchmarks on looks like the following. We run it for both ArrayList and LinkedList, and for different list sizes. The result is passed to the JMH blackhole, to make sure that no JVM optimizations are triggered that would make this measurement irrelevant.
List<Integer> ints = ...; // varies in size
int LAST = ints.size() - 1;
int MIDDLE = ints.size()/2;
// 1st bench
ints.get(0);
// 2nd bench
ints.get(LAST);
// 3rd bench
ints.get(MIDDLE);
You can compare the numbers we show on this page between themselves, since all these benchmarks have been made on the same machine. That being said, there is very little chance that you would get the same numbers on your machine. We encourage you to precisely bench the exact computations you need to do in your application, on a machine and in a context as close as possible to your production environment.
Here are the results for the read first operation.
ArrayList SIZE Score Error Units
Read first 10 1.181 ± 0.022 ns/op
Read first 100 1.200 ± 0.041 ns/op
Read first 1000 1.167 ± 0.009 ns/op
Read first 10000 1.174 ± 0.014 ns/op
LinkedList SIZE Score Error Units
Read first 10 1.127 ± 0.030 ns/op
Read first 100 1.107 ± 0.008 ns/op
Read first 1000 1.121 ± 0.016 ns/op
Read first 10000 1.119 ± 0.014 ns/op
As you can see, the results are the same for both implementations, and do not depend on the size of the list, as expected.
Here are the results for the read last operation.
ArrayList SIZE Score Error Units
Read last 10 1.248 ± 0.020 ns/op
Read last 100 1.232 ± 0.035 ns/op
Read last 1000 1.240 ± 0.019 ns/op
Read last 10000 1.254 ± 0.040 ns/op
LinkedList SIZE Score Error Units
Read last 10 1.493 ± 0.040 ns/op
Read last 100 1.467 ± 0.019 ns/op
Read last 1000 1.475 ± 0.019 ns/op
Read last 10000 1.484 ± 0.042 ns/op
This result is slightly different, and shows a tiny loss of performance in the case of LinkedList. This difference is very small, a fraction of a nanosecond, and not really relevant though.
Reading the Middle Element of a List
The situation is different when you try to reach the middle of the list.
ArrayList SIZE Score Error Units
Read middle 10 1.571 ± 0.055 ns/op
Read middle 100 1.616 ± 0.073 ns/op
Read middle 1000 1.543 ± 0.018 ns/op
Read middle 10000 1.537 ± 0.010 ns/op
LinkedList SIZE Score Error Units
Read middle 10 3.211 ± 0.023 ns/op
Read middle 100 31.118 ± 0.321 ns/op
Read middle 1000 566.079 ± 8.696 ns/op
Read middle 10000 7836.099 ± 902.666 ns/op
As you can see, reaching the middle element of an array is roughly the same as reaching its last element, and does not depend on the size of the array, at least for the size we are testing.
The situation is different for LinkedList. Reaching the middle element is expensive, and depends on the number of elements in the list. Reaching the last element was the same as reaching the first is due to the fact that the LinkedList implementation has a direct reference to the first and the last node of the internal linked list.
To understand why reaching the middle element is expensive, you need to take into account the structure of a linked list, as it is implemented in the LinkedList class.
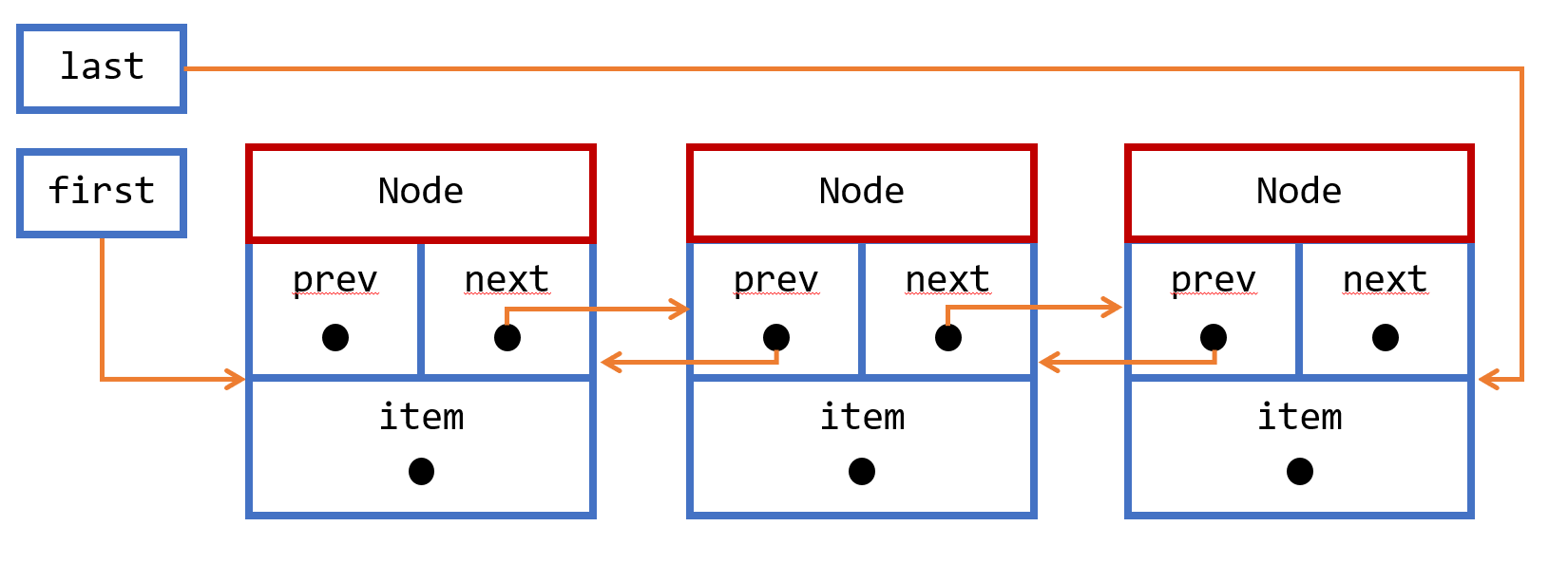
The Java implementation of linked list is a collection of Node objects, where a Node contains three references. One to the next node in the list, one to the previous node in the list, and a third one to the object this node is carrying. So it is in fact a doubly linked list. Plus, the LinkedList class contains two other references: one to the first node, and one to the last node. So reaching the first or last node is fast. On the other hand reading the middle node is not as fast, because the implementation needs to read all the next references until it reaches the node it needs. This is what you observe on the benchmark: reading the middle element of a LinkedList is costly, and becomes more costly as the size of the list grows.
Note that reading the middle node is the worst case scenario. Because it has a reference on the first and last node, the implementation always chooses the shortest path to the element it needs to reach.
This degradation in performance is due to the pointer chasing effect. As you know, reading references triggers the loading of the referenced piece of memory in your CPU cache. If this piece of memory you need to read is already there, then it's a win, and you will get it immediately. If it's not, then it is called a cache miss, you need to fetch it, which takes some time.
You can observe this by creating your linked list in a special way. In the bench we just ran, the linked list is created with the following code. It is created with a stream.
var ints =
IntStream.range(0, LIST_SIZE)
.boxed()
.collect(Collectors.toCollection(LinkedList::new));
Odds are, since we are not in a real application, that all the node objects of this linked list are actually stored close to one another in the memory. So when you read the next reference from a node, odds are that this reference is already in the cache, because it was loaded along with the current node.
Let us imagine another way of creating a linked list, which would make sure that all the nodes are isolated from one another in the memory. In the following example, we create a certain number of node objects between to two node objects of the list we are using for the benchmark. And we make sure to keep a reference on this list during the benchmark, to make sure that the garbage collector will not move our objects in the memory. We can then run the benchmark several times, with different values of SPARSE_INDEX.
var ints = new LinkedList<>();
var intsOther = new LinkedList<>();
for (int i = 0; i < LIST_SIZE; i++) {
ints.add(i);
for (int k = 0; k < SPARSE_INDEX; k++) {
intsOther.add(k);
}
}
Here are the results.
LinkedList SIZE SPARSE Score Error Units
Read middle 1000 0 561.428 ± 4.853 ns/op
Read middle 1000 1 602.401 ± 17.126 ns/op
Read middle 1000 10 944.997 ± 31.920 ns/op
Read middle 1000 100 1509.282 ± 28.749 ns/op
Indeed, pointer chasing hurts the performance of reading random values in a LinkedList. As you can see, having a linked list with nodes randomly distributed in the memory is three times slower than the same linked list with nodes stored in a contiguous way. Odds are that in an application that keeps adding and removing elements from a linked list, this is the situation you will be in.
Iterating Over the Elements of a List
Iterating with an Index and an Iterator
Iterating over the elements of a list can be implemented with two patterns. The first one is the classical one from the Collections Framework, and uses an Iterator. The second one consists in using an index to access all the elements one by one. As you may expect, iterating over the nodes of a LinkedList will probably suffer from pointer chasing, because getting to the next node consists in following a reference.
The two patterns we are using for this benchmark are the following. First, the one that is using an index.
var ints = ...; // LinkedList or ArrayList
for (var index = 0; index < ints.size(); index++) {
var v = ints.get(index);
// pass v to the blackhole
}
And second, the one that is using an Iterator. Note that in the following example, which uses a for-each pattern, the compiler creates an iterator for you in the byte code.
for (var v: ints) {
// pass v to the blackhole
}
For ArrayList, both patterns are roughly the same. Using an index is a little more costly, due to the fact that you need to manage this index. You may be wondering why incrementing an int is more costly than having to manage an iterator. Well, it turns out that the for-each pattern does not expose the iterator in your source code, so it cannot be used for anything else than iterating over this list. When it comes to optimizing your code, the JIT compiler may see that, and in some cases can optimize this piece of code, and avoid the creation of this iterator. You end up with a code that it much faster, because no object is actually created or managed.
ArrayList SIZE Score Error Units
Iterate iterator 1000 1.447 ± 0.024 ms/op
Iterate index 1000 1.986 ± 0.045 ms/op
For LinkedList the situation is different. Using an iterator is more expensive that in the ArrayList case, mostly due to pointer chasing. In the ArrayList case, all you need to do is add an offset to an address on the heap to get to a given element, whereas in the LinkedList implementation, you need to follow a reference, with probably a cache miss if the next node is not there.
Using an index is very costly, and is actually quite a stupid pattern to use. Iterating with an index consists in starting from the beginning of the list, and moving from one node to the other index time, for each of the elements of the list. The complexity of this iteration is O(n^2). Never use this pattern on a LinkedList. It takes about half a second to iterate over a linked list of 1000 elements, where it takes only 4ms with an iterator.
LinkedList SIZE Score Error Units
Iterate iterator 1000 4.950 ± 0.116 ms/op
Iterate index 1000 584.889 ± 4.396 ms/op
Iterating on a Copy of a LinkedList
Iterating is twice as expensive on a LinkedList than on an ArrayList. So you may be wondering if it would not be more efficient to copy your LinkedList in a regular, array-based list, before iterating over it. Of course this process will consume memory, and you may have issues if this list is modified while you are iterating over it, but it may be worth taking a look at the performance.
Let us examine the following pattern, and run the benchmark.
var ints =
IntStream.range(0, 1_000)
.boxed()
.collection(Collection.toCollection(LinkedList::new));
var copyOfInts = ints.stream().toList();
for (var v: copyOfInts) {
// pass v to the blackhole
}
The result is the following. As you can see, for a list of 1000 elements, copying the list consumes 4% of the time it takes to iterate over its elements. So if you can afford the memory overhead, and need to iterate several times, or randomly access elements several times, copying a linked list to an array-based list pays off very quickly.
Note that we are using the Stream.toList() pattern to create this list. First, it creates an unmodifiable list, and second it uses an optimization to create an array of the right size up front, instead of growing this array as you add elements to it, which is what ArrayList and Collectors.toList() are doing.
LinkedList SIZE ITERATION Score Error Units
toList then iterate 1000 1 5.182 ± 0.347 ms/op
toList then iterate 1000 10 14.031 ± 0.793 ms/op
toList then iterate 1000 100 100.104 ± 7.422 ms/op
At this point, the data shows one important thing: pointer chasing and cache misses can kill your performance. This has an impact on any reference based data structure: linked list of course, but also trie trees, binary trees, read black trees, skip lists, and to a lesser extent, hash maps.
Inserting Elements in a List
Linked lists are known for their amazing performance when it comes to inserting an element at a random position. Inserting something is just about moving the next reference of the previous node to the node you need to insert, and the same for the previous reference of the next node. This indeed looks like a pretty inexpensive thing to do. Apart from the fact that, in order to do that, you need to access the previous and the next node. And you already saw in the previous example that this is very expensive.
On the other hand, inserting an element in an array-based list seems more complex. You need to move the right part of the array one cell to the right to create some room for the element you want to insert. Moving the content of an array sounds like something that is not cheap to do.
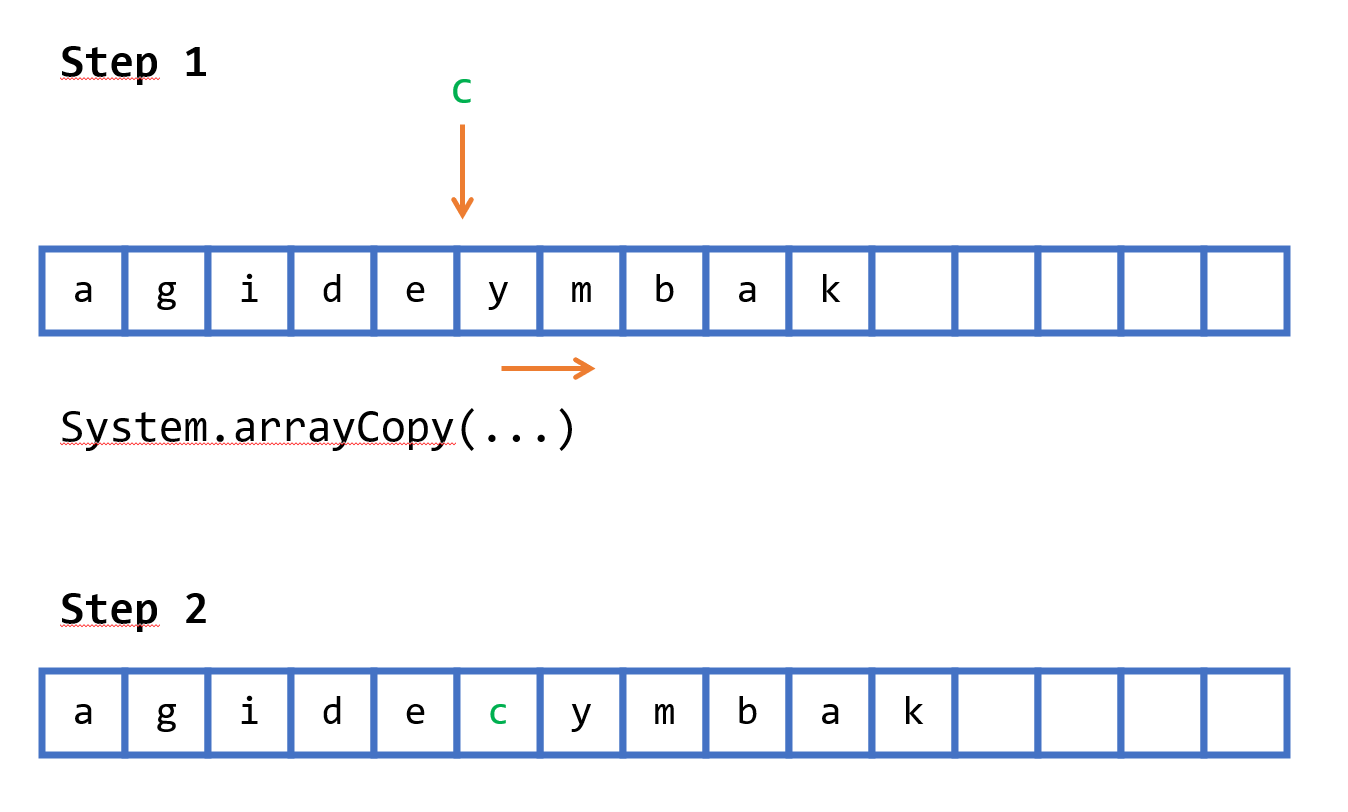
And, by the way, deleting an element is the same. For a linked list you need to rearrange the pointers of the two nodes, and for an array, you need to copy a part of the array to the left.
The two algorithms are different, guessing which one is the fastest is not easy, so let us measure the performance.
Inserting Elements in a LinkedList
Let us consider three cases: inserting at the beginning of the list, in the middle, and at the end. Inserting at the end is more like adding an element to the list.
We expect the following. Since LinkedList has a direct reference to the first and the last nodes of the chain, we should not see much difference between inserting at the beginning and at the end, and it should not depend on the size of the list. Inserting in the middle on the other hand, should be more costly, and this cost should increase with the size of the list.
This is what we observe for the insertion at the beginning. The difference when the size of the list increases is not significant.
LinkedList SIZE Score Error Units
Insert first 10 7.002 ± 0.306 ns/op
Insert first 100 7.126 ± 0.424 ns/op
Insert first 1000 7.561 ± 0.371 ns/op
Insert first 10000 7.738 ± 0.614 ns/op
And the same for adding an element at the end. The difference with the insertion at the beginning is still there, and still very small.
LinkedList SIZE Score Error Units
Adding 10 9.135 ± 0.137 ns/op
Adding 100 9.076 ± 0.082 ns/op
Adding 1000 9.795 ± 0.399 ns/op
Adding 10000 9.549 ± 0.202 ns/op
Inserting in the middle by index is indeed much more costly, and this cost grows with larger lists. The price you pay to reach these middle elements is high. This has been measured with a sparse linked list, that is with node elements that are not stored contiguously in memory.
LinkedList SIZE Score Error Units
Insert middle 10 10.641 ± 0.679 ns/op
Insert middle 100 49.122 ± 1.808 ns/op
Insert middle 1000 584.870 ± 6.925 ns/op
Insert middle 10000 46157.961 ± 379.327 ns/op
Inserting Elements in an ArrayList
You may be thinking that inserting an element is just about moving a part of the array one cell to the right. But there is another case you need to take into account, which is the resizing of this array. You cannot add an element in an array that is full. What the ArrayList implementation does in that case, is that it copies the full array in a larger array, and then adds your element. The size of the new array is computed from the size of the current array, and grows with a factor of 1.5. So if you keep adding elements in a loop for instance, this growing operation triggers less and less often.
So let us examine the two situations: inserting in an array that can accommodate your new element, and the situation where the array is full.
When the array can accommodate the element you add, then things goes as expected. Inserting at the last position, that is adding an element barely depends on the size of the array. The increase of the computing time is probably due to a cache miss to reach the end of the array when it becomes too big. But there is no significant difference between an ArrayList of size 1_000 and 10_000. Inserting in the middle is more expensive due to the copy of the rest of the array to be able to insert the element. As you can expect, if you insert at the beginning, which is the most expensive operation, moving the array is more expensive, simply because you are moving twice the amount of elements.
ArrayList SIZE Score Error Units
Adding 10 2.215 ± 0.053 ns/op
Adding 100 2.184 ± 0.027 ns/op
Adding 1000 5.607 ± 0.856 ns/op
Adding 10000 5.240 ± 0.777 ns/op
ArrayList SIZE Score Error Units
Insert middle 10 23.708 ± 0.370 ns/op
Insert middle 100 25.399 ± 0.241 ns/op
Insert middle 1000 56.061 ± 0.840 ns/op
Insert middle 10000 294.457 ± 4.689 ns/op
ArrayList SIZE Score Error Units
Insert first 10 22.380 ± 0.266 ns/op
Insert first 100 26.929 ± 0.385 ns/op
Insert first 1000 78.958 ± 1.429 ns/op
Insert first 10000 717.892 ± 9.242 ns/op
When the array cannot accommodate the element, then the implementation of ArrayList copies its internal array to a larger array. This operation was not triggered in the previous benchmarks, but you can easily create another one, with a full array, to measure the impact this resizing has.
Comparing these first benchmarks with the same benchmark in a larger array shows you the price of allocating a new array and copying the current array in the new one. As expected it depends on the size of the array, and it is quite expensive. Fortunately it doesn't happen often. The number of resize operations grows sub-linearly, the growth factor decreases with each resize. It should remind you that whenever you can create an array with the right size upfront, you should do it to save on this reallocation.
ArrayList SIZE Score Error Units
Adding in a full array 10 19.300 ± 2.953 ns/op
Adding in a full array 100 45.488 ± 3.922 ns/op
Adding in a full array 1000 432.351 ± 46.055 ns/op
Adding in a full array 10000 4140.668 ± 329.160 ns/op
As the cost of reallocation is much higher than the cost of insertion, you can expect to see little difference between inserting in the middle or at the beginning of your list. Which is the case on the two following benchmarks.
ArrayList SIZE Score Error Units
Insert middle in a full array 10 39.334 ± 1.588 ns/op
Insert middle in a full array 100 61.037 ± 2.130 ns/op
Insert middle in a full array 1000 451.471 ± 27.247 ns/op
Insert middle in a full array 10000 4638.632 ± 360.694 ns/op
ArrayList SIZE Score Error Units
Insert first in a full array 10 28.288 ± 0.656 ns/op
Insert first in a full array 100 52.935 ± 2.457 ns/op
Insert first in a full array 1000 452.179 ± 37.434 ns/op
Insert first in a full array 10000 4762.783 ± 133.468 ns/op
Comparing the Insertion for LinkedList and ArrayList
As you can see, ArrayList outperforms LinkedList for all the operations but one. This can be unexpected, because from an algorithm point of view, LinkedList compares better, especially for the insertion operation. But because this efficient algorithm is executed on a hardware that makes pointer chasing very costly, this overhead becomes dominant and makes it inefficient.
There are two points though, where LinkedList performs better: the insertion at the beginning of a list. LinkedList has two advantages over ArrayList:
- the insertion time does not depend on the size of the list,
- because there is a direct reference to the first element of the list, pointer chasing can only happen once, at most.
Plus, it does not depend on how you added the elements of your LinkedList. The fact that the node are distributed randomly in your heap memory has no impact. And the same goes for adding elements at the end of your list. The performance are almost the same, because in that case ArrayList does not need to move any element of its internal array. This last operation is not as fast as for ArrayList, but it is predictable. If your ArrayList implementation decides that it is time to grow its internal array, then the performance hit may be very high.
Even if the price of a reallocation is high, because it happens rarely, the hit on your application performance is averaged out. Remember that you can (and should!) create your ArrayList with the right size whenever you can. On the overall, it is wrong to think that the price of a reallocation is a relevant argument to prefer LinkedList over ArrayList.
So these are two use cases where LinkedList is interesting, and performs better, or is almost on par with ArrayList: operating at the beginning or at the end of the list. The operation could be reading, inserting, or deleting, that actually costs the same as inserting.
And indeed, LinkedList are very good stack or queue implementations. When it comes to regular lists, not so good. They are almost always outperformed by ArrayList.
Analyzing the Memory Consumption of LinkedList and ArrayList
How do ArrayList and LinkedList perform memory wise? This one is a trick question, as different JVM may handle memory differently, and a single JVM can have different strategies depending on the amount of memory it is running in.
We are using the JOL OpenJDK tool to measure the memory consumed by these implementations.
In general, storing a given amount of objects in a LinkedList requires more memory than storing the same objects in an ArrayList. In most of the cases much, much more. There is actually a good reason for that: each reference in a LinkedList is stored in a Node object, that also stores two other references, one to the previous Node, and the other to the next Node. This typically requires 24 bytes, because you need to add the header of the Node object. You can check the Node class in the LinkedList class. It is a private class, and has no JavaDoc.
The exact memory consumption can vary, depending on your application. If your application consumes less than 32GB, this number is most of the time exact. For instance, for 1000 objects, a LinkedList will consume a little more than 24kB of memory, where an ArrayList only consumes a little less than 5kB.
There is one case though, where storing your object in an ArrayList is more costly. If you have only one object to store, then the ArrayList you create may wrap array of size 10. It depends on how you have created your ArrayList. And in that case, your ArrayList consumes more memory than a LinkedList: 80 bytes versus 56 bytes.
So if you have many one element lists, then you can come across memory consumption issues. Let me put it in the other way. If you have an application that creates many array lists, and you come across unexpected memory issues, then you should investigate more precisely how many objects your array lists are holding. It could be that you are actually creating almost empty array lists, that consume a lot of, unused, memory.
The exact memory consumption of a one element ArrayList actually depends on how you created this ArrayList.
Here are different patterns and their results.
var intsV1 = new ArrayList<Integer>();
intsV1.add(1); // wraps an array of size 10
var intsV2 = new ArrayList<Integer>();
intsV2.addAll(List.of(1)); // wraps an array of size 10
var intsV3 = new ArrayList<Integer>(List.of(1)); // wraps an array of size 1
If you are in that case you still have several solutions. Using LinkedList is one of them, but maybe you can also use one of the non-modifiable implementations that you can get with the List.of() methods. These are more efficient than ArrayList, and LinkedList, memory wise: only 26 bytes for just one element. You need to keep in mind that they are unmodifiable though.
One last point on memory consumption. Because of the way it is working, a LinkedList always accommodate for the exact number of elements it needs to carry. There is no empty node in a LinkedList. On the other hand, an ArrayList grows automatically when its internal array is full.
It turns out, that there is no mechanism in ArrayList that shrinks this array automatically. So if your application removes many elements from your ArrayList, you may reach a situation where the internal array is large, because it was needed at some point, but becomes almost empty, consuming memory for nothing.
In fact, an ArrayList holds an array that is copied in a larger array when it becomes full. But this array is never copied to a smaller array if it becomes almost empty. So, if you run into memory issues, this is definitely a point that you also need to investigate.
Fortunately there is a ArrayList.trimToSize() method that trims the capacity of its internal array to the size of your list. By the way if you call ArrayList.trimToSize() on a one element ArrayList, then it becomes smaller than the one element LinkedList. You will immediately save memory by calling this method, but you will also have to grow your list again the next time you add an element to it.
| Memory consumption for 1 element | |
|---|---|
| ArrayList | 76 bytes |
| ArrayList | 44 bytes (after trimToSize()) |
| LinkedList | 56 bytes |
| List.of() | 26 bytes |
| Memory consumption for 1_000 elements | |
|---|---|
| ArrayList | 4_976 bytes |
| LinkedList | 24_032 bytes |
As you can see, despite the fact that ArrayList can be managing an array that is not fully used, it still uses much less memory than the corresponding LinkedList. Managing these node objects consumes 24 bytes for each object, which is much more than managing a partially empty array. The worst case scenario is when ArrayList has to reallocate. During this time, ArrayList has two arrays: the old one, and the new one that is larger. Even in this case ArrayList still consumes less memory than LinkedList. So if memory is a concern in your application, ArrayList is always your best choice.
How Many Elements Can You Store in a Given Heap?
Suppose that for some reason, your application keeps adding elements to a list. Let us compare the number of elements you can manage with an ArrayList and a LinkedList in a given heap memory of size H. We are only interested in the memory consumption of the lists, not the size of the objects you are storing.
A LinkedList needs one node object for each element, which is of size 24 bytes. So in that case the math is simple: you can store a maximum of H/24 elements.
For ArrayList, the situation is a little more complex. If the internal array of ArrayList is full, then you can store H/4 elements. But there may be a portion of this array that is not used, so on an average it may be less than that. If you just reallocated your array, then 33% of it is not used, so on an average you are using about 6 bytes per object. So, in an application that keeps adding elements to a list, ArrayList is more efficient than LinkedList by a factor between 6 and 4.
The worst case scenario is when your ArrayList is conducting a reallocation. There is no wastage here: your old array is full. But during that process, ArrayList has a reference on an array that is full, plus another array that is of size 1.5*N. So during that process ArrayList consumes 10 bytes per object. Even in this worst case scenario, ArrayList is still more efficient than LinkedList by a factor of 2.4.
For a given heap size, ArrayList can always store more elements than LinkedList, even during its reallocation process. It can be up to 6 times more.
Which Implementation Should You Choose?
ArrayList is a good implementation, that outperforms LinkedList in almost all the classical list operations, at least when what you need is a regular list. Even if the LinkedList implementation is implemented with better algorithms, it is a pointer based structure, that suffers from pointer chasing. So iterating is costly, getting an element by its index is costly, which has an impact on all the classical operations: inserting, replacing, deleting. Even if these operations by themselves cost less on LinkedList than on ArrayList, the performances are killed by the fact that accessing the right element is very expensive, due to pointer chasing.
ArrayList are not so good at inserting, because of this System.arraycopy() operation, but still mostly better than LinkedList. ArrayList reallocation is a quite costly operation, but that is used very rarely, as that you can avoid if you know how many elements you need to store in your list. You can avoid resizing by creating your ArrayLists that are large enough to hold all the objects you need, up front.
There is one case where LinkedList performs better than ArrayList: it is the case where what you need is to access only the first or the last element of your list. That is, when what you need is actually a stack or a queue, not a regular list. And, bytheway, LinkedList indeed implements Queue. Note that LinkedList also implements Deque. If what you need is a double-ended queue (Deque), you should prefer the ArrayDeque implementation.
Memory wise, you need to keep in mind that a LinkedList consume much more memory that an ArrayList. There is one exception though: a one element LinkedList may consume less memory than a one element ArrayList, in the case where your ArrayList actually wraps an array of size 10. You can fix this situation by using List.of(), or by calling ArrayList.trimToSize().
In the case you need lists that carry a small amount of items, and you are running your application in a memory constrained environment, creating an ArrayList with an initial capacity of size 2 works well. It occupies only 48 bytes to store 0, 1, or 2 elements. If you continue adding elements, it expands the array to 3, then 4, then 6 elements (respectively 56, 56, and 64 bytes total). It is smaller than LinkedList at all nonzero sizes. It is even smaller than the default-capacity ArrayList until you get to size 9; and it's the same size as the trimmed ArrayList up until size 7.
You can see that on the following table, obtained with the following process.
- Create a list:
new ArrayList<>(2),new LinkedList<>(),new ArrayList<>(), andnew ArrayList<>().trimToSize(). - Check the initial memory consumption.
- Keep adding elements one by one, then trim the last list, and check the memory consumption.
| ArrayList of size 2 | Linked List | Default ArrayList | Default trimmed ArrayList | |
|---|---|---|---|---|
| 0 | 40 | 32 | 40 | 40 |
| 1 | 48 | 56 | 80 | 48 |
| 2 | 48 | 80 | 80 | 48 |
| 3 | 56 | 104 | 80 | 56 |
| 4 | 56 | 128 | 80 | 56 |
| 5 | 64 | 152 | 80 | 64 |
| 6 | 64 | 176 | 80 | 64 |
| 7 | 80 | 200 | 80 | 72 |
| 8 | 80 | 224 | 80 | 72 |
| 9 | 80 | 248 | 80 | 80 |
| 10 | 96 | 272 | 80 | 80 |
One last thing to keep in mind: an ArrayList never shrinks. Invoking a remove operation, or a clear operation, does not copy its internal array to a smaller array. You can fix this situation by calling ArrayList.trimToSize(), which triggers the copy of this internal array to a smaller array.
Last update: March 3, 2025